 Go to App
Go to App Subscribe
Subscribe


In the previous article, we fixed a DNS time out issue in our EKS cluster by upgrading the kernel and using the NodeLocalDNS. Then we got into another issue of getting 503 from services randomly. We are using Istio Service Mesh .
Problem :-
We started debugging to find out where and why connections are getting dropped. From the logs, we found out that the requests were reaching to the istio-proxy sidecar but it was not forwarded to the application container. Most of the 503 errors were for inbound traffic in the istio access log. On further debugging and istio documentation, we found that when a request arrives at Istio-proxy, it opens up a connection with the application container. These connections are cached at istio for better performance. But from the application side these connections have some idle timeouts. 503 errors were a result of istio forwarding requests to one of those closed connection from the application side due to idle timeout. We thought to disable the istio-proxy caching, but it would affect the performance.
Enabling retry in Virtual Service :-
We considered to add a retry option, which will basically retry if any request fails due to some specific connection errors. By doing so we can avoid disabling the istio-proxy caching and handle closed connections. This is defined in VirtualService. With following configuration, it will try to attempt the request 3 times in case of mentioned error. We are setting the retries on gateway-error, connect-failure and refused-stream errors. perTryTimeout can also be configured.
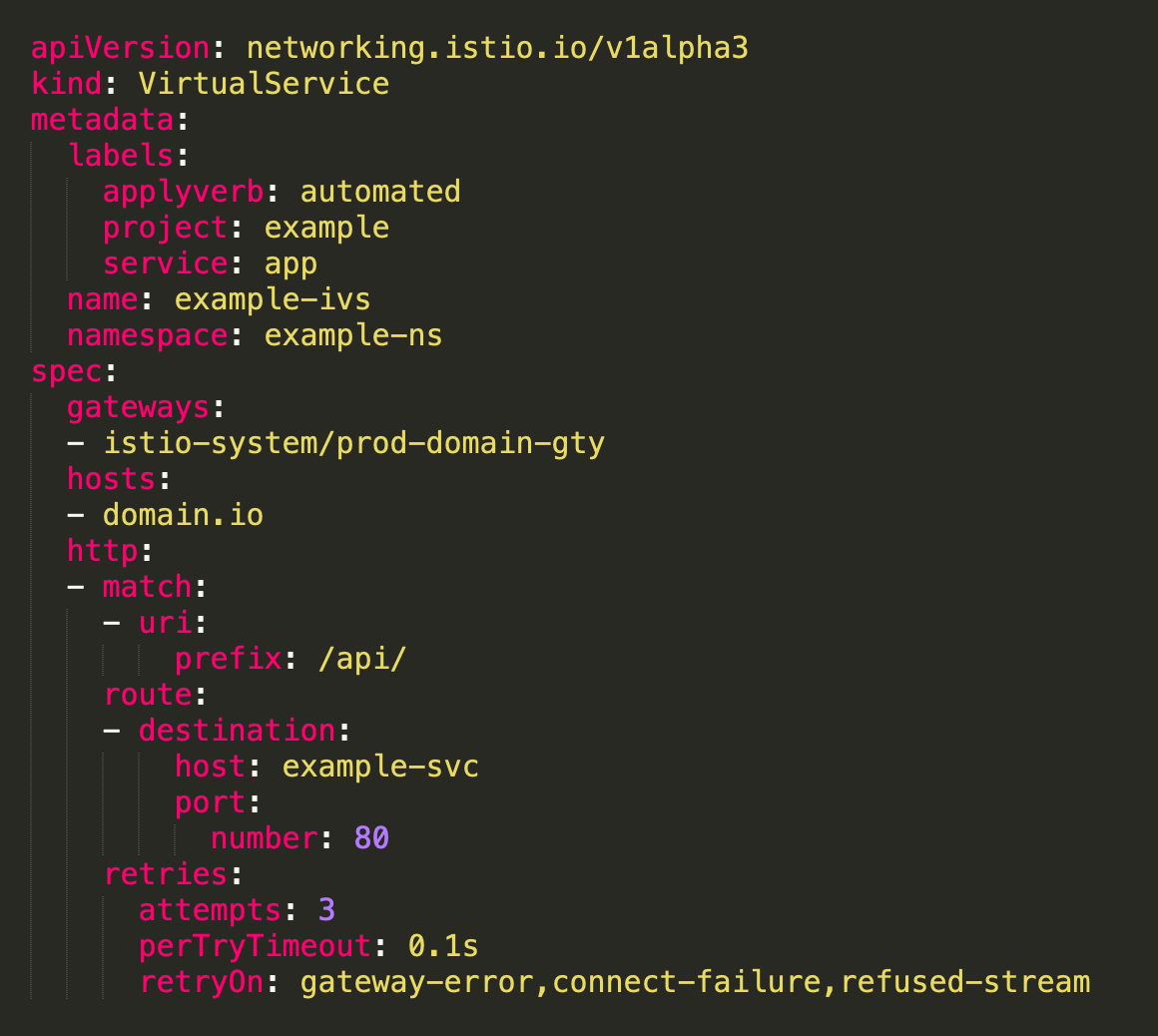
We have a retry time out of 0.1 sec and it varies from application to application. It will do an attempt to reinitiate the request.
To test it, we created a dummy application and an end point which will return 503 in response code. We verified in istio logs that requests were retied thrice before returning the error response to the client. Following is a basic flask app, which returns a message and 503 in response code for the route /dnschecker.
@app.route('/dnschecker')
def home_page():
return "This is to check DNS timeouts issue in istio-proxy", 503End point to trigger the retry attempts,
https://host/dnscheckerIn the log we can see 3 consecutive attempts,
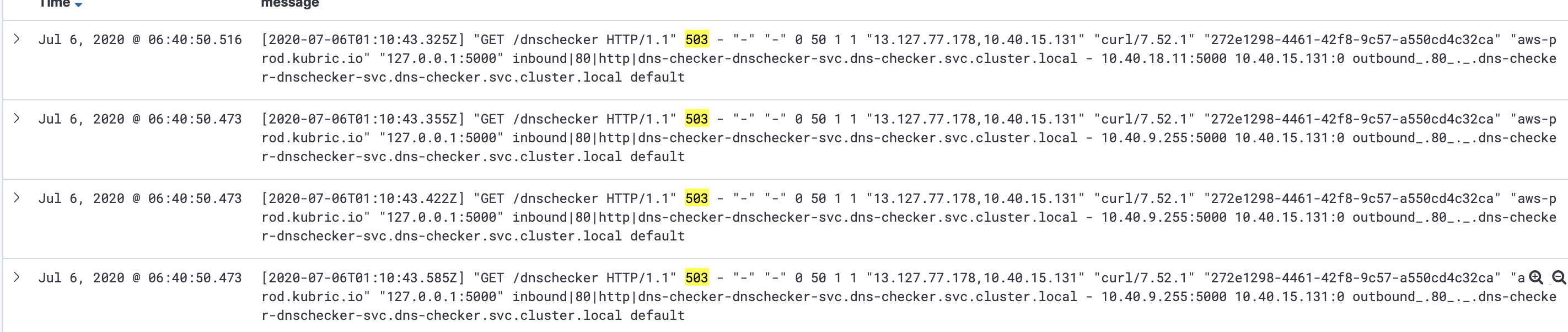
We rolled it out to all of our services. We monitored it for next few days and noticed that each of the failed requests is having three retries.
Please let us know how has been your experience with Kubernetes cluster in the comment section.
Stay tuned for more interesting stories.