 Go to App
Go to App Subscribe
Subscribe


An approach for speedy tree walking 🏃 on a remote fileshare
This post covers a modified Breadth First Search (BFS) approach for performing fast tree traversal on a remote fileshare. It combines multi-threading and multi-processing to achieve a 90x speedup over a naive Depth First Search solution.
This post covers a modified Breadth First Search (BFS) approach for performing fast tree traversal on a remote fileshare. It combines multi-threading and multi-processing to achieve a 90x speedup over a naive Depth First Search solution. We created it to generate faster diffs for Kubric's sync system.
One of Kubric's products is a smart asset search & storage system. Using it, you can sync with other storage systems like Dropbox, Amazon S3, Azure Files, Google Drive etc.
A problem any sync solution faces is this: how do you incrementally sync between the source and destination when either of them doesn't provide change notifications? The most obvious solution is to periodically compute a diff between the source and destination and copy over only the diff. The ability to list all the files in the source and the destination is needed for computing a diff. This is problematic because many services (such as Azure Files) do not provide any way to get a complete listing of files in one go.
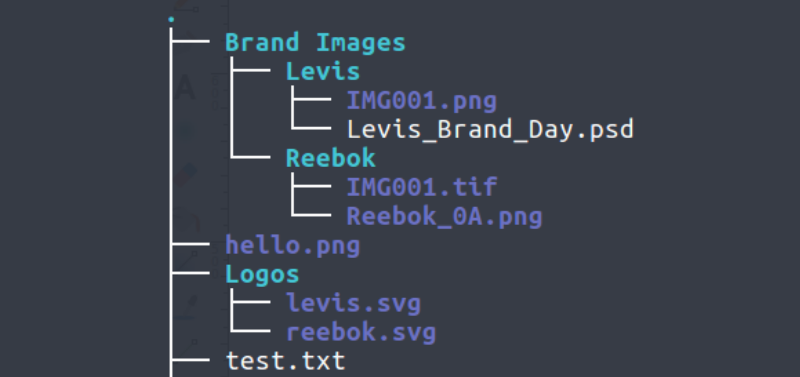
So, our task is this - given a directory tree with hundreds of thousands of files and folders, we want to get a list of absolute paths of all the files in the tree as fast as possible. As an added edge of complexity, the directory tree is an Azure fileshare and the only way to interact with it is by either mounting the drive or by using the Azure Files HTTP API.
Our first instinct was to mount the fileshare as a disk. As it turns out Azure Fileshares can be mounted with CIFS on a Linux box. This turned out to be quite terrible and slow. A single ls or cd command would take multiple seconds to run.
So we decided to try out the HTTP API with a naive Depth First Search. Start from the root and keep going down until you hit a leaf. Rinse and repeat. This was definitely faster than the mounted disk but it was still too slow.
So how did we do it?
We went with an approach which performs level order traversal. Let's say we have a method to get a list of files and directories inside a directory. Let's call it get_files_and_dirs. At each level,
- we append child files of the current level to our overall list of files
- child directories of the current level are appended to a list (let's call it
next_level_dirs) - get_files_and_dirs is called with
next_level_dirsas the input via aThreadPoolExecutor(threads are great for this problem because it's I/O intensive)
We keep doing this while next_level_dirs is not empty. Since we have multiple starting directories, it makes sense to have a process pool. In the pool, each process performs the steps described above for one starting directory.
This is the implementation -
def get_files_and_dirs(file_service, directory_name):
""" Uses the file_service object to return a tuple containing a
list of files and a list of directories in a given directory in
the directory tree.
"""
generator = file_service.list(directory_name)
files = []
directories = []
for file_or_dir in generator:
full_path = directory_name + '/' + file_or_dir.name
files.append(full_path) if isinstance(file_or_dir, File)\
else directories.append(full_path)
return files, directories
def get_all_paths(file_service, directory_name):
""" Get all the paths (including nested paths) inside a given
directory
"""
file_paths, directories = get_files_and_dirs(file_service, directory_name)
with ThreadPoolExecutor(max_workers=10) as executor:
while True:
if not directories:
break
next_level_dirs = []
futures = []
for directory in dirs:
# saves all the futures that executor.submit returns
futures.append(executor.submit(get_files_and_dirs,
file_service, directory))
for future in as_completed(futures):
# uses concurrent.futures.as_completed to wait
# on the list of futures
files, dirs = future.result()
file_paths.extend(files)
next_level_dirs.extend(dirs)
directories = next_level_dirs
return file_paths
pool = Pool(pool_size)
get_all_paths_partial = partial(get_all_paths, file_service)
path_lists = pool.map(get_all_paths_partial, folders)We found that a thread-pool of size 10 worked the best after some tests on a GCP Compute Engine n1-standard-2 instance (2 vCPUs / 7.50 GB RAM). We had around 500,000 files and 12,000 directories in the file share . These were the results of the tests -
| Processes | Threads | Final Time (seconds) |
|---|---|---|
| 1 | 1 | 7258 (this is the naive approach) |
| 1 | 50 | 199 |
| 2 | 100 | 103 |
| 2 | 70 | 104 |
| 2 | 50 | 102 |
| 2 | 30 | 97 |
| 2 | 10 | 80 |
| 2 | 5 | 123 |
So we managed to go from 7258 seconds to 80 seconds ➡️ a 90x speedup 🙂. As I mentioned earlier, we implemented this for getting a list of files from Azure Files. However, you can use this approach with any storage product as long as you have an API to list files in a directory.
We are hiring! If you are interested in building smart systems around Scalable Search, Storage, Orchestration & Rendering drop us a mail at [email protected]